调试前端页面的时候,有时候会遇到点击弹窗后从另外一个标签页打开页面的情况,这个时候如果手工去打开调试工具,页面加载之前的网络接口调用就追踪不到了,这个问题查询了一下,从 Chrome 50 版本开始支持页面跳转调试器自动跟踪。只是默认情况下,此功能没有开启,需要手工开启此功能。
具体开启此功能的操作如下:
1. 打开浏览器控制台(F12)/开发者工具
2.使用三点菜单(F1,控制台右上角X号旁边的那个按钮打开 setting 栏)
调试前端页面的时候,有时候会遇到点击弹窗后从另外一个标签页打开页面的情况,这个时候如果手工去打开调试工具,页面加载之前的网络接口调用就追踪不到了,这个问题查询了一下,从 Chrome 50 版本开始支持页面跳转调试器自动跟踪。只是默认情况下,此功能没有开启,需要手工开启此功能。
具体开启此功能的操作如下:
1. 打开浏览器控制台(F12)/开发者工具
2.使用三点菜单(F1,控制台右上角X号旁边的那个按钮打开 setting 栏)
本文介绍了 Intel QAT 技术方案,通过 Multi-Buffer 技术和 QAT 硬件加速卡的两种方式实现对 TLS 的加速
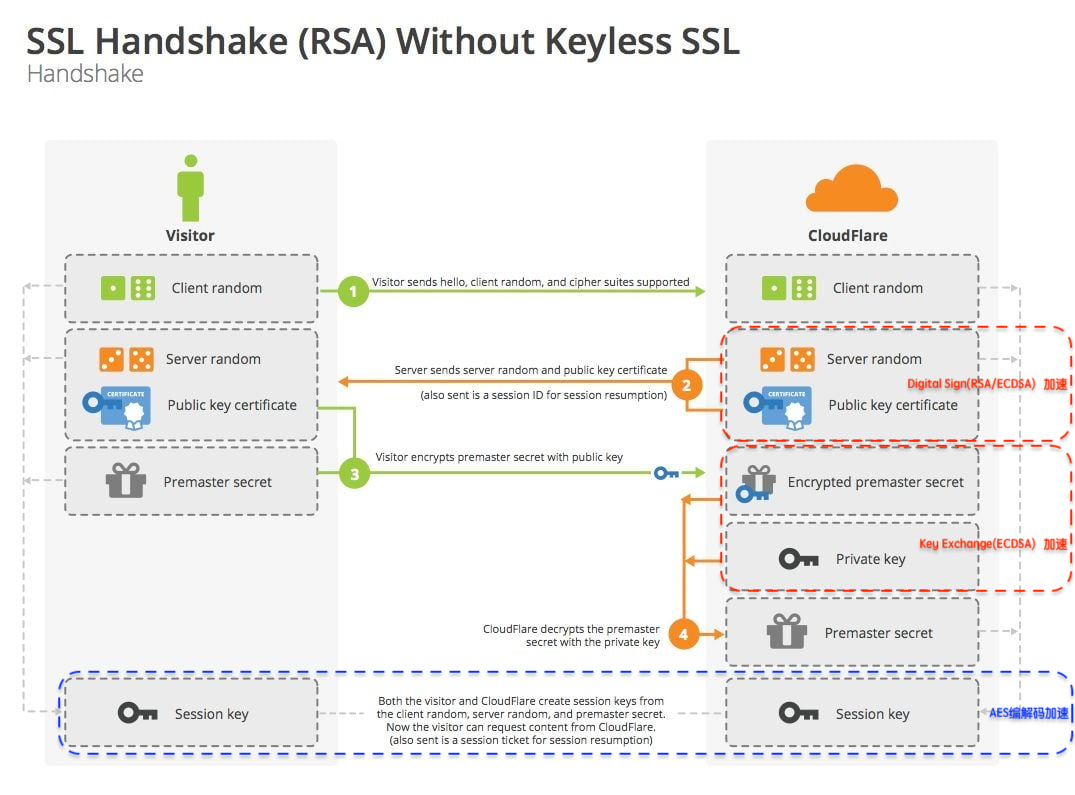
当前 TLS 已经成为了互联网安全的主要传输协议,TLS 带来更高的安全性的同时,也带来了更多的性能开销。特别是在建连握手阶段,TLS 的 CPU 开销,相对于 TCP 要大很多。
业界在优化 TLS 性能上已经做了很多软件和协议层面的优化,包括:Session 复用、OCSP Stapling、TLS1.3等。然而在摩尔定律"失效"的今日,软件层面的优化很难满足日益增长的流量,使用专用的硬件技术卸载 CPU 计算成为目前通用的解决方案。本文将介绍 Intel 在 TLS 加速领域提供的 QAT 技术方案。
Intel 提供了 TLS 异步加速的完整解决方案: Intel QuickAssist Technology(QAT),简称 Intel QAT 技术。
如下图所示,QAT 支持加速的密码算法覆盖了 TLS 的整个流程,包括:握手阶段的签名、秘钥交换算法,数据传输的 AES 加解密算法等。
QAT 提供了对称与非对称两类密码算法的支持,主要包括:
注:QAT 加速的优势主要体现在非对称加密上,从官方的整体性能数据看,非对称算法性能提升 1.6~2 倍,对称算法性能提升 10%~15%
QAT Engine 是 QAT 技术方案的核心模块,主要的作用是作为应用程序和硬件之间的中间层,负责 “加解密操作的输入输出数据” 在用户应用程序与硬件卡之间进行传递,主要操作就是IO的读写。
QAT Engine 是以 OpenSSL 第三方插件的方式提供给用户,这个意味用户可以使用 OpenSSL 标准的 API,就可以实现对 TLS 的加速,只需要对原有代码做 OpenSSL 异步改造,就可以享受 QAT 技术带来的 TLS 性能加速,业务侵入性较小。
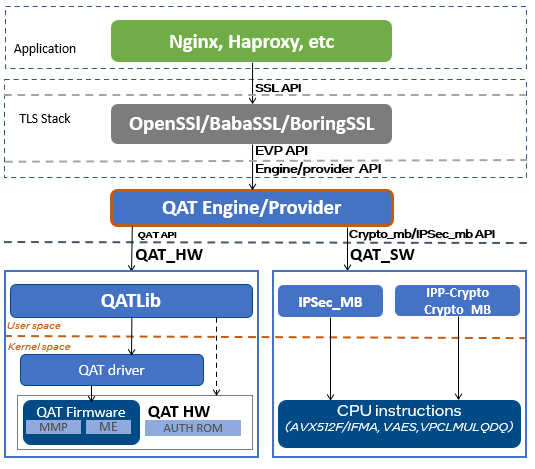
如上图所示,QAT Engine 支持两种加速方式:
下面将介绍软件和硬件两种加速路径的实现方式。
Intel 从 Whitely 平台开始加入了新的指令集,结合 Intel Multi-Buffer 技术,实现对密码算法的 SIMD 优化方案。
Intel Multi-buffer 基本原理就是使用 CPU 的 SIMD 机制,通过 AVX-512 指令集并行处理数据,来提升RSA/ECDSA算法性能。
Intel 的 Multi-Buffer 方案,实际上是对应 Intel 两个开源工程( Multi Buffer 技术实现的通用密码算法底层lib库),集成在 QAT Engine 里,从而实现软件加速。

1、IP SEC lib
2、IPP CRYPTO lib
简而言之,QAT 的软件加速的本质就是通过 AVX-512 指令集进行并行处理优化,针对并发场景性能有显著提升(下文有针对 Multi-Buffer 优化场景的性能测试)。
除了通过 Multi-Buffer 技术进行软件加速外,QAT Engine 还支持 QAT 硬件加速卡,通过将密码算法的计算卸载(OffLoad)到硬件加速卡,实现性能加速。
硬件加速核心是将 TLS 中的非对称加解密操作剥离出来,放到硬件加速卡里计算,即解放了 CPU,同时专用的硬件加速卡也提供了更高的加解密性能,这是典型的硬件 OffLoad 技术方案。
下图为典型的 Nginx+ Intel QAT Software Stack + QAT 硬件加速卡的典型应用场景:
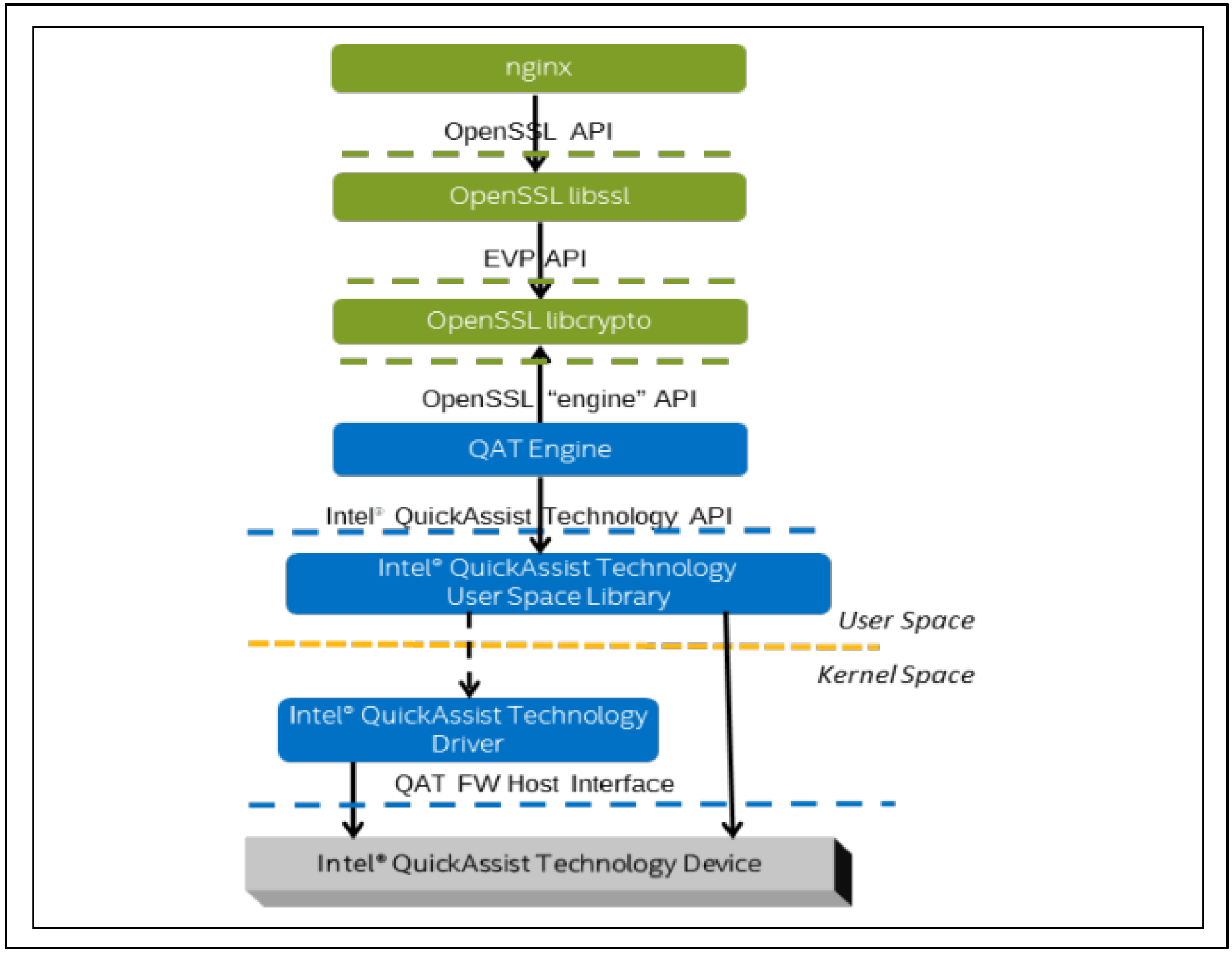
这个典型应用场景包括四个部分:
Intel QAT 依赖了 OpenSSL 的两个特性 OpenSSL Async Mode 和 OpenSSL Engine:
基于两个特性,应用程序的加解密操作只需要保持使用原来相同 OpenSSL API,只需要做异步模式的兼容。另外,可以在调用 OpenSSL 的 API 时,指定到 Engine QAT上就行,不需要做任何额外的修改,就可以使用 QAT 卡进行加解密加速。
通过上面的介绍,我们可以看到 QAT 卡的本质是让一部分原本由 CPU 进行的计算转移到 QAT 卡上进行,因此提高 QAT 的利用率,降低 CPU 的切换开销和等待时间是性能最大化的核心工作。
OpenSSL 未启用异步ASYNC模式时,OpenSSL 调用是同步阻塞的,直到QAT_Engine返回结果。如下图的同步模式,在并发处理执行流的场景,大量CPU处于空闲等待的状态(图中虚线表示CPU处于空闲状态),无法有效地利用CPU。
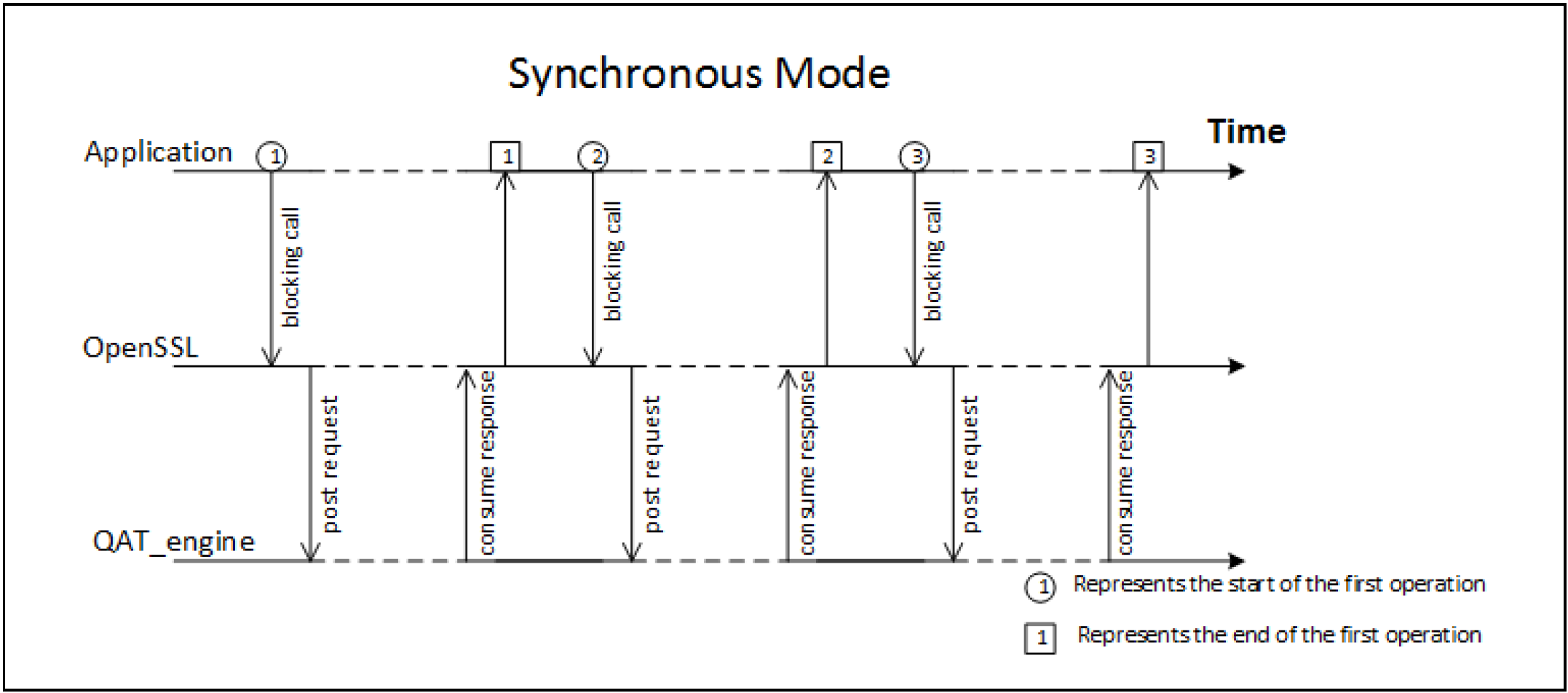
OpenSSL 开启异步 ASYNC 模式后,OpenSSL 调用是非阻塞的。如下图的异步模式,OpenSSL 的调用不需要等待QAT_engine的处理完成,可以有效地利用 CPU,提高 QAT 的利用率,提升并发处理性能。
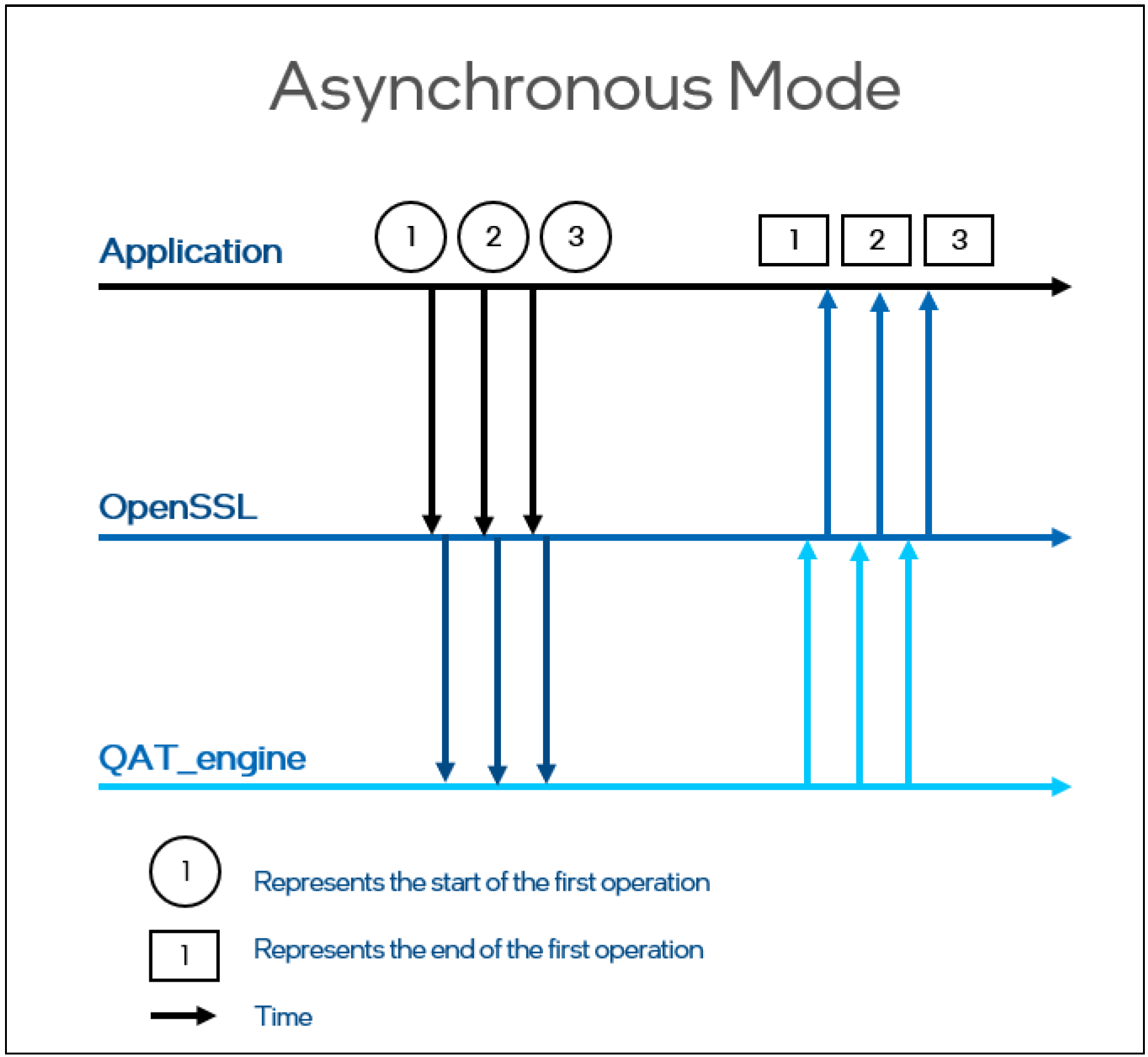
通过 OpenSSL 的同步和异步模式的对比,可以看到 OpenSSL-1.1.1 新增的异步 Async 特性,支持了异步非阻塞调用,提高了 QAT 的利用率,可以显著提升加解密性能。
接下来还有一个问题,CPU 如何知道 QAT 卡完成了计算呢?
Async模块为了达到并行的目的,在单线程中实现了协程(async job)。加解密操作抽象为job,多个job同时运行,使用协程进行调度。
在async job执行的过程中,当计算操作提交给QAT卡后,CPU 可以把当前任务暂停,切换上下文(保存/恢复栈,寄存器等)返回给用户态。
用户态需要主动去poll这个async job的状态,是否是ASYNC_FINISHED状态。如果是,说明之前的任务已经完成,则可以继续后面的操作(取回加密/解密结果)。
注:QAT Engine 通过轮询来获取QAT卡的计算状态,基本原理是启动一个线程,不停的调用qatdriver的polling api,轮询获取qat的计算状态,得到相应结果后,写入eventfd,唤醒async job。
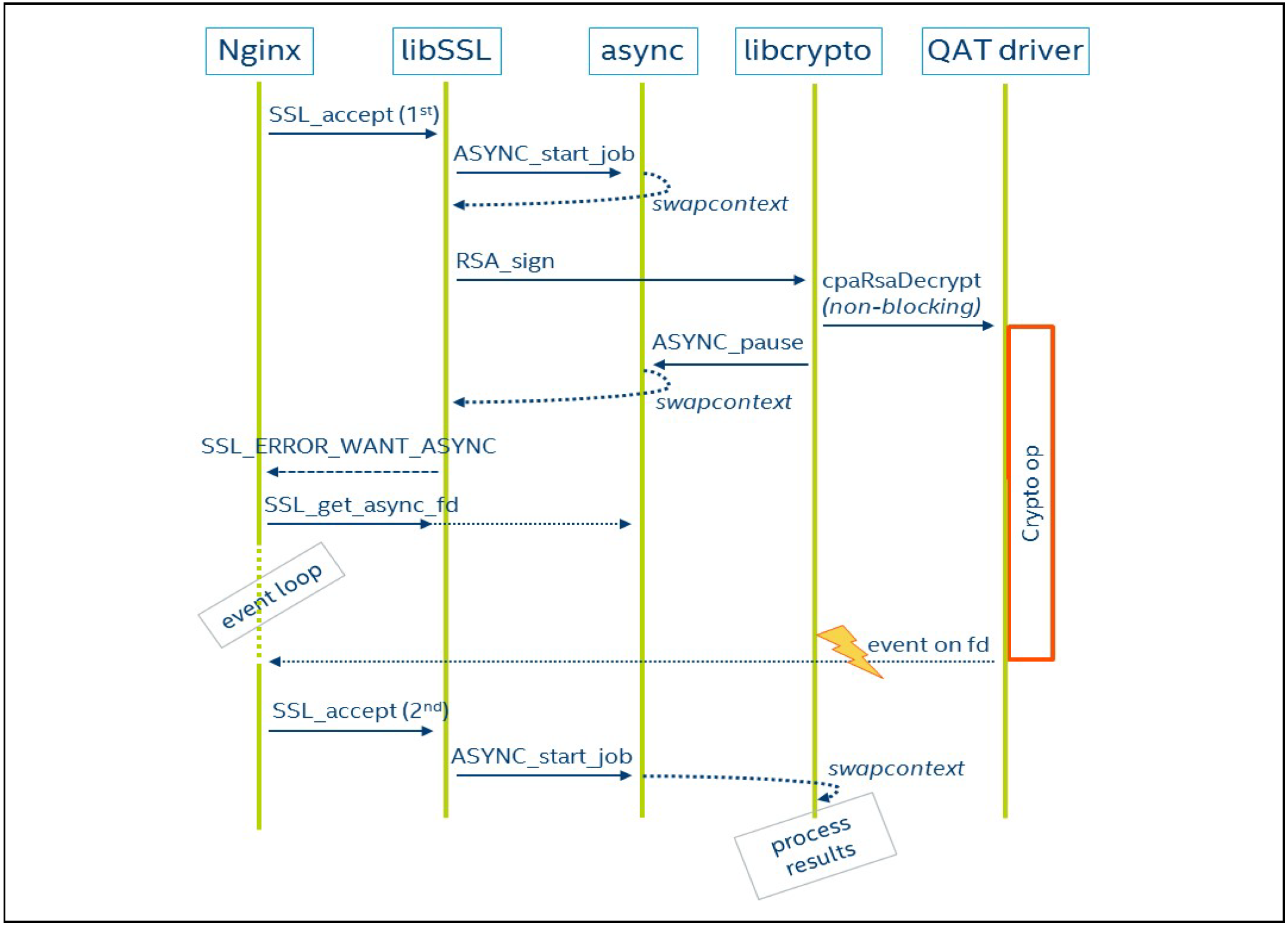
如上图所示,QAT Engine Async的基本流程为:
通过上面的介绍,我们了解了 QAT 技术方案的基本原理,下面我们看下 QAT 的实际加速效果。
QAT Multi-Buffer 加速方案,依赖的 OpenSSL、QAT Engine、ipp-crypto、 Intel-ipsec-mb 软件栈都是开源项目,我们可以方便的使用 OpenSSL Speed 原生加解密算法对 Multi-Buffer 方案进行性能评估。
硬件环境
软件环境
测试数据
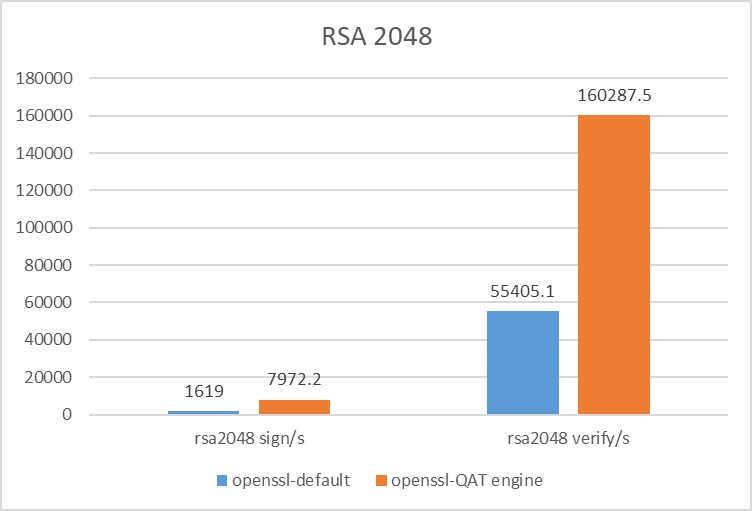
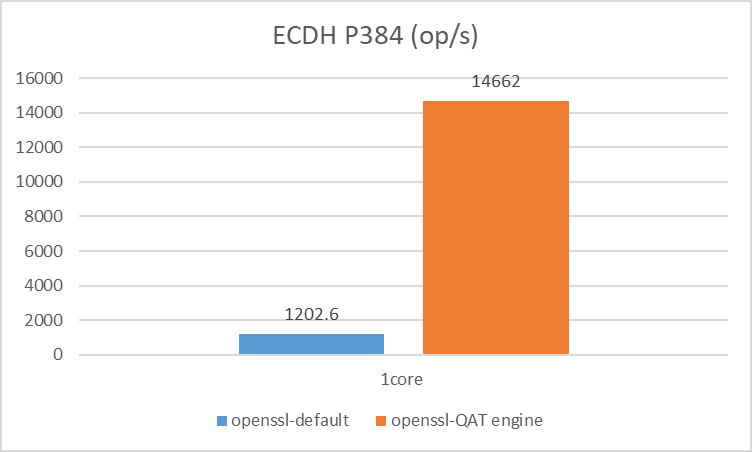
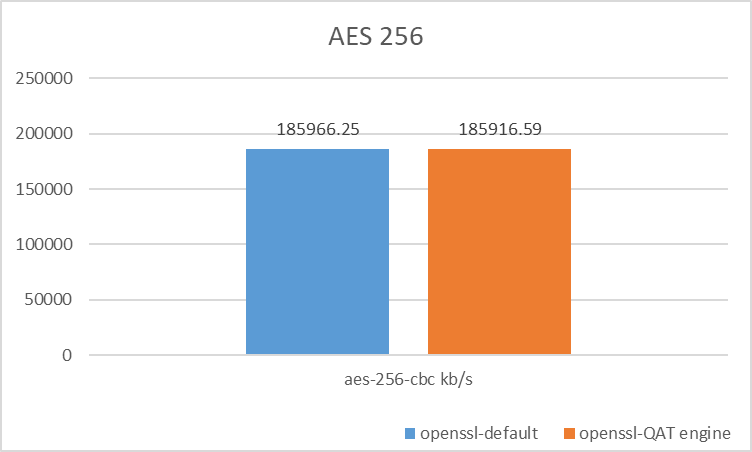
TLS 握手阶段的签名和秘钥交换算法
对称加解密算法
根据性能测试结果,QAT 的加速优势在于 TLS 握手阶段的签名和秘钥交换算法,适合频繁进行 TLS 建连的应用场景,比如:Nginx 网关、长连接网关等。
本文介绍了 Intel QAT 技术方案,并讨论了方案提供的 Multi-Buffer 软件加速以及 QAT 硬件加速两种方式。同时,通过性能评估测试,我们可以看到 QAT 技术对 TLS 握手阶段的加解密算法有显著的性能提升。
最后,我们讨论一下 Intel QAT 技术的优缺点和应用场景:
主要的优点
主要的缺点
除了加解密算法之外,Intel QAT 还支持压缩和解压缩、随机数生成、数字签名、视频编解码等算法。Intel QAT 主要可以用于以下场景:
总的来说,Intel QAT 可以将计算密集型任务从 CPU 中分离出来,显著提高系统的性能和能效比,可以广泛应用于计算密集型任务的加速,包括网络安全、数据处理、云计算、存储加速、视频处理等多个领域。
在 Manjaro 22、Ubuntu 23.04、Fedora 38、macOS 14.6.1 等最新的 Linux/macOS 发行版中运行 pip install时,通常会收到一个错误提示:error: externally-managed-environment,即“外部管理环境”错误,但这不是一个 bug。
如果您想阅读,这是完整的错误信息:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
$ pip3 install please-cli error: externally-managed-environment × This environment is externally managed ╰─> To install Python packages system-wide, try 'pacman -S python-xyz', where xyz is the package you are trying to install. If you wish to install a non-Arch-packaged Python package, create a virtual environment using 'python -m venv path/to/venv'. Then use path/to/venv/bin/python and path/to/venv/bin/pip. If you wish to install a non-Arch packaged Python application, it may be easiest to use 'pipx install xyz', which will manage a virtual environment for you. Make sure you have python-pipx installed via pacman. note: If you believe this is a mistake, please contact your Python installation or OS distribution provider. You can override this, at the risk of breaking your Python installation or OS, by passing --break-system-packages. hint: See PEP 668 for the detailed specification. |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
$ pip3 install please-cli error: externally-managed-environment × This environment is externally managed ╰─> To install Python packages system-wide, try brew install xyz, where xyz is the package you are trying to install. If you wish to install a Python library that isn't in Homebrew, use a virtual environment: python3 -m venv path/to/venv source path/to/venv/bin/activate python3 -m pip install xyz If you wish to install a Python application that isn't in Homebrew, it may be easiest to use 'pipx install xyz', which will manage a virtual environment for you. You can install pipx with brew install pipx You may restore the old behavior of pip by passing the '--break-system-packages' flag to pip, or by adding 'break-system-packages = true' to your pip.conf file. The latter will permanently disable this error. If you disable this error, we STRONGLY recommend that you additionally pass the '--user' flag to pip, or set 'user = true' in your pip.conf file. Failure to do this can result in a broken Homebrew installation. Read more about this behavior here: <https://peps.python.org/pep-0668/> note: If you believe this is a mistake, please contact your Python installation or OS distribution provider. You can override this, at the risk of breaking your Python installation or OS, by passing --break-system-packages. hint: See PEP 668 for the detailed specification. |
“外部管理环境”错误背后的原因:Manjaro 22、Ubuntu 23.04、Fedora 38、macOS 14.6.1 以及其他的最新发行版中,正在使用 Python 包来实现此增强功能。
这个更新是为了避免「操作系统包管理器 (如pacman、yum、apt、homebrew) 和 pip 等特定于 Python 的包管理工具之间的冲突」。
这些冲突包括 Python 级 API 不兼容和文件所有权冲突。
更多详情可以在官方查看:
PEP 668 – Python base environments
通过 "user" 参数要求 pip 安装到用户私有目录下,仅对当前用户有效。建议在当前用户目录下的 ~/.pip/pip.conf 增加如下配置:
|
1 2 3 |
[global] user = true index-url = https://pypi.tuna.tsinghua.edu.cn/simple |
和之前一样,现在您可以直接运行 pip(3) install package_name 命令来安装python模块。
强制删除此警告,回归到熟悉的操作。
将 “x” 替换为实际版本。
|
1 |
$ sudo mv /usr/lib/python3.x/EXTERNALLY-MANAGED /usr/lib/python3.x/EXTERNALLY-MANAGED.bk |
和之前一样,现在您可以直接运行 pip(3) install package_name 命令来安装python模块。
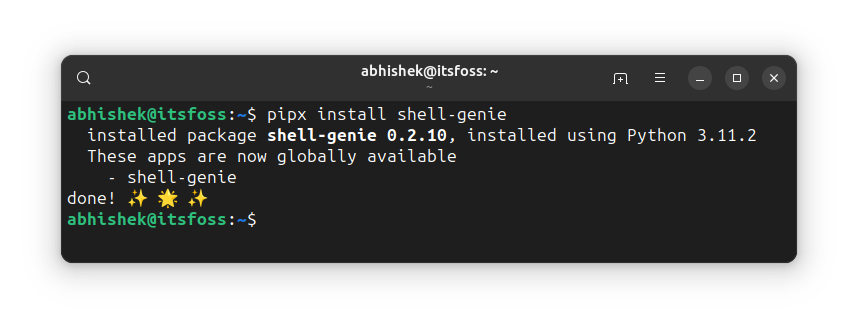
您在上面看到的涉及手动工作。Pipx 使其自动化。
它会自动为您安装的每个应用程序创建一个新的虚拟环境。不仅。它还在 中创建指向它的链接.local/bin。这样,安装该软件包的用户就可以从命令行中的任何位置运行它。
我想这就是大多数桌面 Linux 用户想要的。
使用以下命令在 Ubuntu 上安装 pipx:
|
1 |
$ sudo apt install pipx |
它可能会安装大量的依赖项:
现在将其添加到 PATH 中,以便您可以从任何地方运行。
|
1 |
$ pipx ensurepath |
提示:
您必须关闭终端并重新登录才能发生更改。
现在我们可以使用 Pipx 而不是 Pip 安装 Python 包:
|
1 |
$ pipx install package_name |
这个是一个例子:
提示:
要删除使用 pipx 安装的软件包,请使用 pipx uninstall package_name 命令。
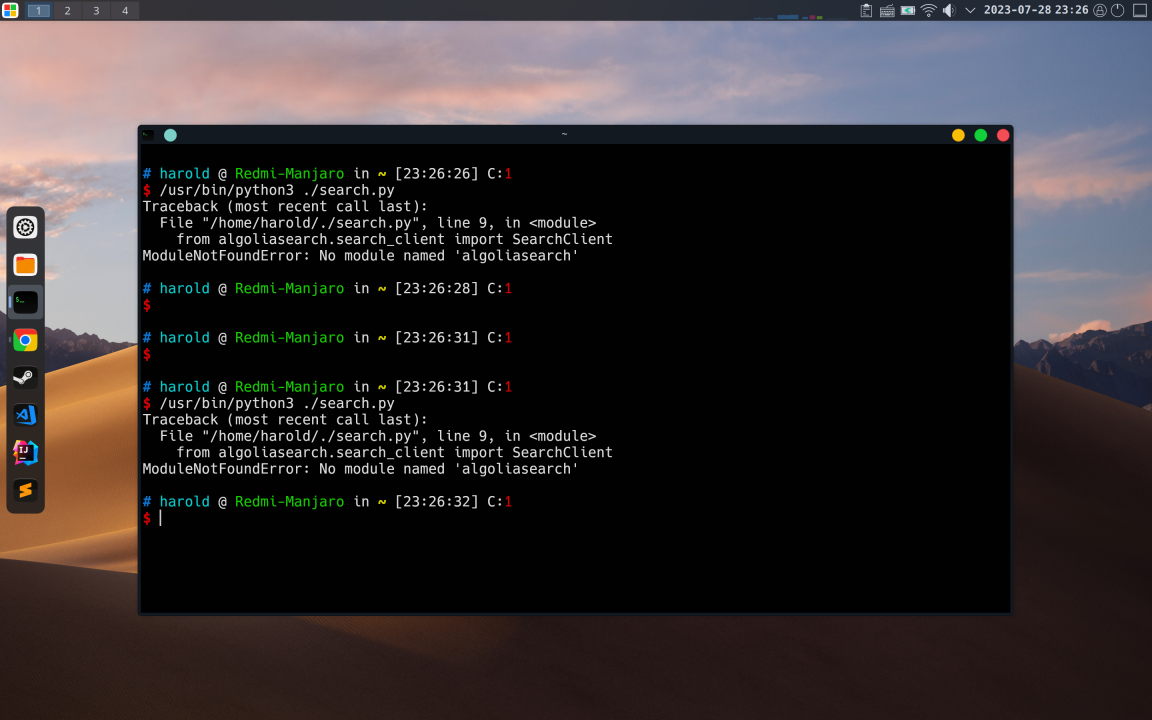
如果您是开发人员,
在运行或构建py文件时遇到如下图 ModuleNotFoundError: No module named 'xxx' 的错误,
推荐切换为该方案,即使用Python虚拟环境。
借助虚拟环境,您可以使用不同版本的包依赖项和Python。这样,您就可以避免包之间的任何冲突。
这种方法适合从事 Python 项目的软件开发人员和程序员。
|
1 2 3 4 5 |
sudo apt install python3-venv #或 sudo apt install python3.10-venv |
|
1 |
$ mkdir -p $HOME/.env && python3 -m venv $HOME/.env/project_name |
现在,您将看到一个.env在您的主目录中,并且在 .env 中,您将拥有项目目录。
每个虚拟环境项目目录中都会有自己的 Python 和 Pip 副本。
|
1 2 3 |
$ $HOME/.env/project_name/bin/python -m pip install --upgrade pip $ $HOME/.env/project_name/bin/python -m pip install algoliasearch |
|
1 2 3 |
$ source $HOME/.env/project_name/bin/activate $ $HOME/.env/project_name/bin/python ./demo.py |
这只是 Python 虚拟环境的一个简短示例。如果您想了解更多信息,这里有一份详细指南。
据我所知,Pip 提供了一种安装 Python 包的舒适方法。然而,一些Python应用程序也打包为APT或其他本机包。在您的发行版存储库中搜索它并从那里安装它(如果可用)。
例如,我试图安装 WoeUSB-ng。如果我使用 Arch Linux,AUR 也提供相同的软件包。
Pip 是一个在系统上获取 Python 包的好工具。个人认为它始终是为 Python 程序员设计的,而不是为最终用户设计的。显然它不能用作原生发行包的替代品,Python 开发人员已经明确表示了这一点。
当然最新的改动的好处是,程序员和最终用户都有替代方案。
在 HuggingFace 上下载模型时,经常会看到模型的名称会带有fp16、GPTQ,GGML等字样,对不熟悉模型量化的同学来说,这些字样可能会让人摸不着头脑,我开始也是一头雾水,后来通过查阅资料,总算有了一些了解,本文将介绍一些常见的模型量化格式,因为我也不是机器学习专家,所以本文只是对这些格式进行简单的介绍,如果有错误的地方,欢迎指正。
量化在 AI 模型中,特别是在深度学习模型中,通常指的是将模型中的参数(例如权重和偏置)从浮点数转换为低位宽度的整数,例如从 32 位的浮点数转换为 8 位整数。通俗地说,量化就像是把一本详细的、用高级词汇写的书简化为一个简短的摘要或儿童版故事。这个摘要或儿童版故事占用的空间更小,更容易传播,但可能会丢失一些原始书中的细节。
量化的目的主要有以下几点:
但是,量化也有一个缺点:它可能会导致模型的精度下降。因为你实际上是在用较低的精度来表示原始的浮点数,可能会损失一些信息,这意味着模型的能力会变差。为了平衡这种精度损失,研究者们开发了各种量化策略和技术,如动态量化、权重共享等,可以在尽量少降低模型能力的情况下,尽可能多地降低模型所需的损耗。打个比方,如果我们一个模型的完整能力是 100,模型大小和推理所需内存也是 100,我们将这个模型量化后,模型的能力可能会降低到 90,但模型大小和推理所需内存可能会降低到 50,这个就是量化的目的。
HuggingFace 上模型名称如果没有特别标识,比如 Llama-2-7b-chat、chatglm2-6b,那么说明这些模型一般是全精度的(FP32,但也有些是半精度 FP16),而如果模型名称中带有fp16、int8、int4等字样,比如Llama-2-7B-fp16、chatglm-6b-int8、chatglm2-6b-int4,那么说明这些模型是量化后的模型,其中fp16、int8、int4字样表示模型的量化精度。
量化精度从高到低排列顺序是:fp16>int8>int4,量化的精度越低,模型的大小和推理所需的显存就越小,但模型的能力也会越差。
以 ChatGLM2-6B 为例,该模型全精度版本(FP32)的大小为 12G,推理所需用到的显存为 12~13G,而量化后的 INT4 版本模型大小为 3.7G,推理所需显存为 5G,可以看到量化后的模型大小和显存需求都大大减小了。
FP32 和 FP16 精度的模型需要在 GPU 服务器上运行,而 INT8 和 INT4 精度的模型可以在 CPU 上运行。
GPTQ 是一种模型量化的方法,可以将语言模型量化成 INT8、INT4、INT3 甚至 INT2 的精度而不会出现较大的性能损失,在 HuggingFace 上如果看到模型名称带有GPTQ字样的,比如Llama-2-13B-chat-GPTQ,说明这些模型是经过 GPTQ 量化的。以Llama-2-13B-chat为例,该模型全精度版本的大小为 26G,使用 GPTQ 进行量化成 INT4 精度后的模型大小为 7.26G。
如果你用的是开源模型LLama,可以使用GPTQ-for-LLaMA这个库来进行 GPTQ 量化,它可以将相关的Llama模型量化成 INT4 精度的模型。
但现在更流行的一个 GPTQ 量化工具是AutoGPTQ,它可以量化任何 Transformer 模型而不仅仅是Llama,现在 Huggingface 已经将 AutoGPTQ 集成到了 Transformers 中,具体的使用方法可以参考这里。
讲 GGML 之前要先说下llama-cpp这个项目,它是开发者 Georgi Gerganov 基于 Llama 模型手撸的纯 C/C++ 版本,它最大的优势是可以在 CPU 上快速地进行推理而不需要 GPU。然后作者将该项目中模型量化的部分提取出来做成了一个模型量化工具:GGML,项目名称中的GG其实就是作者的名字首字母。
在 HuggingFace 上,如果看到模型名称带有GGML字样的,比如Llama-2-13B-chat-GGML,说明这些模型是经过 GGML 量化的。有些 GGML 模型的名字除了带有GGML字样外,还带有q4、q4_0、q5等,比如Chinese-Llama-2-7b-ggml-q4,这里面的q4其实指的是 GGML 的量化方法,从q4_0开始往后扩展,有q4_0、q4_1、q5_0、q5_1和q8_0,在这里可以看到各种方法量化后的数据。
最近在 HuggingFace 上的模型还发现了一些带有GGUF字样的模型,比如Llama-2-13B-chat-GGUF,GGUF其实是 GGML 团队增加的一个新功能,GGUF 与 GGML 相比,GGUF 可以在模型中添加额外的信息,而原来的 GGML 模型是不可以的,同时 GGUF 被设计成可扩展,这样以后有新功能就可以添加到模型中,而不会破坏与旧模型的兼容性。
但这个功能是Breaking Change,也就是说 GGML 新版本以后量化出来的模型都是 GGUF 格式的,这意味着旧的 GGML 格式以后会慢慢被 GGUF 格式取代,而且也不能将老的 GGML 格式直接转成 GGUF 格式。
关于 GGUF 更多的信息可以参考这里。
GPTQ 和 GGML 是现在模型量化的两种主要方式,但他们之间有什么区别呢?我们又应该选择哪种量化方式呢?
两者有以下几点异同:
因此,如果你的模型是在 GPU 上运行,那么建议使用 GPTQ 进行量化,如果你的模型是在 CPU 上运行,那么建议使用 GGML 进行量化。

在 HuggingFace 上,不管是什么格式的量化模型,模型名称中还经常出现一些32g、128g字样,比如pygmalion-13b-4bit-128g,这些又是表示什么意思呢?
128g中的g其实表示的是 groupsize 的意思,在量化技术中,权重可能会被分成大小为 groupsize 的组,并对每组应用特定的量化策略,这样的策略可能有助于提高量化的效果或保持模型的性能。
groupsize 的值有:1024、128、32,GPTQ 默认的 groupsize 值是 1024。如果 groupsize 没有值,那么 groupsize 就为-1( 注意不是 0)。groupsize 会影响模型的准确性和推理显存大小,groupsize 根据同等精度模型准确性和推理显存从高到底的排列顺序是:32 > 128 > 1024 > None(-1),也就是说 None(-1) 是准确性和显存占用最低的,而 32 是最高的。
大型语言模型 (LLM) 是强大的工具,可以为各种任务和领域生成自然语言文本。 最先进的LLM之一是 LLaMA(大型语言模型 Meta AI),这是由 Facebook 的研究部门 Meta AI 开发的一个包含 650 亿个参数的模型。
要在家运行 LLaMA 模型,你需要一台配备强大 GPU 的计算机,能够处理推理所需的大量数据和计算。 在本文中,我们将讨论本地运行 LLaMA 的一些硬件要求。
在消费类硬件上运行 LLaMA 模型有多种不同的方法。 最常见的方法是使用单个 NVIDIA GeForce RTX 3090 GPU。 该 GPU 具有 24 GB 内存,足以运行 LLaMA 模型。 RTX 3090 可以运行 4 位量化的 LLaMA 30B 模型,每秒大约 4 到 10 个令牌。 24GB VRAM 似乎是在消费类台式电脑上使用单个 GPU 的最佳选择。
但是,如果你想运行更大的模型,则必须使用双 GPU 设置。 这将允许你将模型权重放入 VRAM 中。 你还可以使用高级 GPU,例如 NVIDIA A100。 这个GPU非常昂贵,但有40GB内存,可以更好地运行模型。
你还可以在 CPU 上运行 LLaMA 模型。 必须使用模型的 GGML 版本(LLaMA、Vicuna、Alpaca 和 GPT4All)以及名为 llama.cpp 的软件才能使用CPU。 运行 LLaMA 的合适 CPU 是 Core i7 12900K 和 Ryzen 9 5900X。 有关此主题的更多信息,请查看 CPU 部分。
请记住,训练或微调 LLaMA 模型需要比运行模型更多的 VRAM。 这是因为训练过程需要将模型以及训练数据存储在 VRAM 中。 训练所需的 VRAM 量取决于模型的大小和训练数据量。
为了在台式电脑上使用 LLaMA 模型,请查看需要满足的一些硬件要求:
7-19更新:LLAMA 2 权威指南
7-30更新:LLAMA 2本地运行的3个方案
在消费级机器上运行 LLaMA 时,GPU 是最重要的计算机硬件,因为它负责运行模型所需的大部分处理。 GPU的性能将直接影响推理的速度和准确性。
模型的不同变体和实现可能需要功能较弱的硬件。 不过,GPU 仍将是系统中最重要的部分。
4 位量化 LLaMA 模型的 GPU 要求:
| LLaMA Model | Minimum VRAM Requirement | Recommended GPU Examples |
|---|---|---|
| LLaMA-7B | 6GB | RTX 3060, GTX 1660, 2060, AMD 5700 XT, RTX 3050 |
| LLaMA-13B | 10GB | AMD 6900 XT, RTX 2060 12GB, 3060 12GB, 3080, A2000 |
| LLaMA-30B | 20GB | RTX 3080 20GB, A4500, A5000, 3090, 4090, 6000, Tesla V100, Tesla P40 |
| LLaMA-65B | 40GB | A100 40GB, 2x3090, 2x4090, A40, RTX A6000, 8000 |
为了有效运行 LLaMA-7B,建议使用至少具有 6GB VRAM 的 GPU。 适合此模型的 GPU 示例是 RTX 3060,它提供 8GB VRAM 版本。 其他 GPU(例如 GTX 1660、2060、AMD 5700 XT 或 RTX 3050)也具有 6GB VRAM,可以作为支持 LLaMA-7B 的良好选择。
为了获得 LLaMA-13B 的最佳性能,建议使用至少具有 10GB VRAM 的 GPU。 满足此要求的 GPU 示例包括 AMD 6900 XT、RTX 2060 12GB、3060 12GB、3080 或 A2000。 这些 GPU 提供必要的 VRAM 容量来有效处理 LLaMA-13B 的计算需求。
为确保 LLaMA-30B 顺利运行,建议使用至少 20GB VRAM 的 GPU。 RTX 3080 20GB、A4500、A5000、3090、4090、6000 或 Tesla V100 是提供所需 VRAM 容量的 GPU 示例。 这些 GPU 可实现 LLaMA-30B 的高效处理和内存管理。
LLaMA-65B 与至少具有 40GB VRAM 的 GPU 配合使用时,性能最佳。 适用于此型号的 GPU 示例包括 A100 40GB、2x3090、2x4090、A40、RTX A6000 或 8000。这些 GPU 提供充足的 VRAM 容量来处理与 LLaMA-65B 相关的密集计算任务。
每个 LLaMA 模型都有特定的 VRAM 要求,建议的 GPU 是根据其满足或超过这些要求的能力来选择的,以确保相应的 LLaMA 模型平稳高效的性能。
除了 GPU 之外,你还需要一个可以支持 GPU 并处理其他任务(例如数据加载和预处理)的 CPU。 基于 GPQT (GPU) 的模型对 CPU 的要求低于针对 CPU 优化的模型。
适合 LLaMA 的 CPU 是 Intel Core i9-10900K、i7-12700K 或 Ryzen 9 5900x。 但是,为了获得更好的性能,你可能需要使用更强大的 CPU,例如具有 64 核和 128 线程的 AMD Ryzen Threadripper 3990X。 最后,真正重要的是 CPU 的速度。 这才是真正的力量所在。 当在昂贵的服务器 CPU 和高端游戏 CPU 之间进行选择时,后者占据主导地位。
我们必须注意,本文讨论的模型是针对 GPU 的,但也有针对 CPU 的 LLaMa 模型优化器。 例如,GGML 是一种解决方案,可以解决处理大型模型时 GPU 内存带来的限制。 如果你更喜欢使用 CPU,建议运行 GGML 格式的模型文件。
你可以使用名为 llama.cpp(LLaMA 模型的接口)的软件来利用你的 CPU。 llama.cpp 最近的更新引入了新的增强功能,使用户能够在 CPU 和 GPU 之间分配模型的工作负载。 这不仅有利于加载更大的模型,而且还提高了令牌的速度。
这是使用 Ryzen 7 3700X 和 128GB RAM 运行 llama.cpp 的示例。
| GGML Model | Memory per Token | Load Time | Sample Time | Predict Time | Total Time |
|---|---|---|---|---|---|
| LLaMA-7B 4-bit | 14434244 bytes | 1270.15 ms | 325.76 ms | 15147.15 ms / 117.42 ms per token | 17077.88 ms |
| LLaMA-13B 4-bit | 22439492 bytes | 2946.00 ms | 86.11 ms | 7358.48 ms / 216.43 ms per token | 11019.28 ms |
| LLaMA-30B 4-bit | 43387780 bytes | 6666.53 ms | 332.71 ms | 68779.27 ms / 533.17 ms per token | 77333.97 ms |
| LLaMA-65B 4-bit | 70897348 bytes | 14010.35 ms | 335.09 ms | 140527.48 ms / 1089.36 ms per token | 157951.48 ms |
除了GPU和CPU之外,你还需要足够的RAM(随机存取存储器)和存储空间来存储模型参数和数据。 4 位 LLaMA-30B 的最低 RAM 要求为 32 GB,可以将整个模型保存在内存中,而无需交换到磁盘。 但是,对于较大的数据集或较长的文本,你可能需要使用更多 RAM,例如 64 GB 或 128 GB。
CPU 和内存之间的带宽是一个关键因素,我想强调它的重要性。 当生成单个 token 时,整个模型需要从内存中读取一次。 假设你有 Core i9-10900X(4 通道支持)和 DDR4-3600 内存,这意味着吞吐量为 115 GB/s,而你的型号大小为 13 GB。 在这种情况下,理论限制约为每秒 8.8 个令牌,无论你的 CPU 有多快或有多少个并行核心。
RAM 的大小取决于 GGML 量化的类型和你使用的模型(LLaMA、Alpaca、Wizard、Vicuna 等)。
这些是 在CPU上使用 LLaMA 模型的内存 (RAM) 要求:
| GGML Model | Original size | Quantized size (4-bit) | Quantized size (5-bit) | Quantized size (8-bit) |
|---|---|---|---|---|
| 7B | 13 GB | 3.9 – 7.5 GB | 7.5 – 8.5 GB | 8.5 – 10.0 GB |
| 13B | 24 GB | 7.8 – 11 GB | 11.5 – 13.5 GB | 13.5 – 17.5 GB |
| 30B | 60 GB | 19.5 – 23.0 GB | 23.5 – 27.5 GB | 28.5 – 38.5 GB |
| 65B | 120 GB | 38.5 – 47.0 GB | 47.0 – 52.0 GB | 71.0 – 80.0 GB |
在 CPU 上运行时基于内存 (RAM) 速度的模型 (8GB) 推理速度:
| RAM speed | CPU | CPU channels | Bandwidth | *Inference |
|---|---|---|---|---|
| DDR4-3600 | Ryzen 5 3600 | 2 | 56 GB/s | 7 tokens/s |
| DDR4-3200 | Ryzen 5 5600X | 2 | 51 GB/s | 6.3 tokens/s |
| DDR5-5600 | Core i9-13900K | 2 | 89.6 GB/s | 11.2 tokens/s |
| DDR4-2666 | Core i5-10400f | 2 | 41.6 GB/s | 5.1 tokens/s |
速度为理论最大值,取决于操作系统和系统负载。
LLaMA的最低存储要求是1TB NVMe SSD,可以存储模型文件和数据文件,读写速度很快。 但是,为了更多数据或备份目的,你可能需要使用更多存储空间,例如 2 TB 或 4 TB SSD。
选择高速存储。 选择具有出色顺序速度的 PCIe 4.0 NVMe SSD,以促进存储和系统 RAM 之间的快速数据传输。
量化 LLM使用更少的位数来存储和处理模型的权重和激活。 这使得它们的 GPU 部署更快、更高效。
4 位量化 LLM 每个权重或激活仅使用 4 位。 这意味着它们比全精度模型占用更少的内存和计算时间。 它们可以在 VRAM 容量较低的 GPU 上平稳运行。
8 位量化 LLM 每个权重或激活使用 8 位。 与全精度模型相比,这仍然减少了内存和计算成本,但不如 4 位量化那么多。 它们需要更多的 GPU 内存和计算能力才能良好运行。 它们更适合具有高 VRAM 容量和计算能力的 GPU。
总而言之,4 位量化 LLM 效率更高,并且可以在 VRAM 容量较低的 GPU 上运行。 8 位量化 LLM 的效率稍低,需要具有高 VRAM 容量和计算能力的 GPU。
| LLaMA Precision | GPU Memory Requirements | Computational Demands | Suitable GPU |
|---|---|---|---|
| Native (32-bit) | Higher requirements | Higher computational demands | GPUs with larger VRAM capacities and high computational capabilities |
| 16-bit Quantized | Moderate requirements | Moderate computational demands | GPUs with moderate VRAM capacities and good computational capabilities |
| 8-bit Quantized | Relatively higher requirements | Slightly higher computational demands | GPUs with larger VRAM capacities and higher computational capabilities |
| 4-bit Quantized | Lower requirements | Lower computational demands | GPUs with limited VRAM capacities |
正如你所看到的,LLaMA 的精度对其 GPU 内存需求和计算需求有直接影响。 原生(32 位)LLM 需要最多的 GPU 内存和计算能力,而 4 位量化 LLM 需要最少。
适用于 LLaMA 的 GPU 取决于其精度以及您想要使用它执行的特定任务。 如果您需要在各种任务上运行大型 LLaMA,那么您将需要具有大 VRAM 容量和高计算能力的 GPU。 如果您只需要在几个特定任务上运行小型 LLaMA,那么您可以使用具有较小 VRAM 容量和较低计算能力的 GPU。
需要注意的是,随着量化级别的降低,模型的准确性也会降低。 这是因为精度降低可能会导致模型预测出现错误。
最适合你的量化级别取决于你的具体需求和要求。 如果需要一个小而高效的模型,那么你可能需要考虑使用 4 位或 8 位量化模型。 但是,如果你需要高度准确的模型,那么可能需要使用 16 位模型。
添加第二个 GPU 可能不会像预期那样加快文本生成速度。 瓶颈似乎阻碍了增加更多计算能力的简单解决方案。 一些测试显示出令人惊讶的结果,低端 GPU 每秒生成令牌的速度比高端 GPU 更快。 其原因尚不清楚,文本生成程序可能需要更好的优化才能很好地使用双 GPU 设置。
双 GPU 设置总共具有更多 VRAM,但每个 GPU 仍然有其自己的 VRAM 限制。 30B LLaMA 需要大约 20GB VRAM,因此两个 RTX 3090 GPU(每个都有 24GB VRAM)仍然只有 24GB VRAM 可用。 该模型应适合一个 GPU 的 VRAM 才能正常运行。
但是,如果模型太大而无法容纳单个 GPU 的 VRAM 并且需要利用系统 RAM,则使用多个 GPU 确实可以加快该过程。 在这种情况下,每个 GPU 可以处理模型的一部分,并且计算负载在它们之间分配。 这种并行化可以提高超过单个 GPU 的 VRAM 容量的大型模型的速度。
因此,在处理具有高 VRAM 要求的大型模型时,通常会采用多个 GPU。 它可以有效利用资源并加速训练或推理过程。
将像 65B LLaMA 这样的大型语言模型拆分到具有模型并行性的多个 GPU 上可能会很困难,并且可能会导致通信延迟。 通过 GPU 拆分和同步模型的参数和计算需要仔细编码,并且可能并不总是能大幅提高性能。
双 GPU 设置可能不适用于某些软件。 某些机器学习框架或库可能无法完全使用多个 GPU,并且可能需要额外的工作来设置和优化系统以使用双 GPU。
这些限制意味着,将双 GPU 设置用于 30B LLaMA 的可能优势与难度和潜在问题进行比较非常重要。 有时,获得更强的单GPU或尝试其他优化方法可能是更好的方法。
创建一个包含主板、CPU 和 RAM 的平台。 GPU 处理训练和推理,而 CPU、RAM 和存储管理数据加载。 选择支持 PCIe 4.0(或 5.0)、多个 NVMe 驱动器插槽、x16 GPU 插槽和充足内存 DIMM 的主板。 建议使用单线程速度较高的 CPU,例如 Ryzen 5000 或 Intel 第 12/13 代。
为了在响应质量方面获得最佳性能,建议在具有至少 20GB VRAM 的 GPU 上运行 8 位 13B 模型或 4 位 30B 模型。 两种型号都提供相似的质量响应,VRAM 可用性应该是决定因素。 投资具有张量核心的 Nvidia GPU 以增强性能。 考虑 RTX 30 系列或 RTX 40 系列等选项,例如 RTX 3090 24GB、RTX 4090 24GB,以获得最佳性能。
就每秒生成的令牌而言,13B 模型通常比 30B 模型运行得更快。 虽然确切的速度差异可能有所不同,但与 30B 模型相比,13B 模型往往会在生成速度方面提供显着的改进。
目标是至少 1.5 倍 VRAM 容量或两倍 VRAM 以获得最佳性能。 当使用 128GB 或更多 RAM 时,主板和 CPU 的选择变得至关重要。
高顺序速度 PCIe 4.0 NVMe SSD 的重要性主要在于将初始模型加载到 VRAM 中。 模型加载后,SSD 对生成速度(令牌/秒)的影响很小。
拥有足够的常规 RAM(最好是 VRAM 容量的两倍)对于初始模型加载至关重要。 模型一旦加载,对实际生成速度的影响是有限的。 确保初始加载期间有足够的常规 RAM 对于流畅的体验至关重要。
CPU 的单线程速度主要对于初始模型加载非常重要,而不是在生成期间运行模型。 CPU的作用在数据预处理、模型加载和其他不依赖GPU的操作等任务中更加突出。
如果你需要将文本生成速度从 15 个令牌/秒提高到 30 个令牌/秒,设置整个 PC 的文字克隆可能比添加第二个 3090 卡更有效。 将整体系统资源(包括 CPU 和 RAM)加倍可能会在提高文本生成速度方面产生更好的结果。
由于 GPU 本身的内部带宽优势,单个 GPU 通常比多 GPU 设置提供更快的性能。
投资具有足够容量为所有组件供电的高质量电源。 选择通风良好的宽敞机箱以获得最佳散热效果。
虽然 DDR5 和 Zen 4 或 AM5 等未来平台具有优势,但稳定性和兼容性可能会有所不同。 考虑投资具有良好 PCIe 插槽布局和内存支持的高端主板,以实现未来的升级。
请记住,虽然这些提示和技巧提供了基于经验的见解,但各个系统配置和性能可能会有所不同。 始终建议对不同的设置进行试验和基准测试,以找到最适合你的特定需求的解决方案。
为了应对频繁的事件调用所带来的性能瓶颈,我们需要引入防抖(debounce)和节流(throttle)这两个利器。
防抖:抑制不必要的高频事件
防抖是一种技术,它可以在一定时间内抑制不必要的高频事件。在鸿蒙应用开发中,防抖可以用来优化事件处理,例如按钮点击事件。
防抖的工作原理是:当一个事件被频繁调用时,防抖函数会将事件放入一个计时器中。在这个计时器中,事件将在一个指定的等待时间后执行。如果在等待时间内又收到了该事件的调用,那么计时器将被重新设置,等待时间将从头开始计算。
节流:限制事件调用的频率
节流是一种技术,它可以限制事件调用的频率。在鸿蒙应用开发中,节流可以用来优化输入框中的输入事件处理。
节流的工作原理是:当一个事件被频繁调用时,节流函数会将事件放入一个令牌桶中。在这个令牌桶中,事件将按照一个固定的速度执行。如果令牌桶已满,那么事件将被丢弃。
防抖与节流的比较
防抖和节流都是用来处理高频事件的利器,但是它们的工作方式不同。
防抖和节流可以在鸿蒙应用开发中得到以下应用:
示例代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
/** * 防抖函数 * * 用法: * * Text() { * Span($r("app.string.text")) * } * .onClick(debounce(() => { * // do click * })) * * @param fn { Function } 需要进行防抖处理的函数 * @param debounceMs { number } 防抖限制的时间,单位(毫秒) */ export function debounce(fn: Function, debounceMs: number = 100) { let timer: number = 0; let cancelTimer = false; return () => { if (cancelTimer) { clearTimeout(timer); cancelTimer = false; } timer = setTimeout(() => { timer = 0; cancelTimer = false; fn(); }, debounceMs); cancelTimer = true; }; } /** * 节流函数 * * 注意:要求第一次事件发生的时候立即执行,然后再进行节流操作 * * 如果先节流后执行会导致用户感觉到明显的响应延迟,造成响应卡顿的假象 * * 用法: * * Text() { * Span($r("app.string.text")) * } * .onClick(throttle(() => { * // do click * })) * * @param fn { Function } 需要进行节流处理的函数 * @param throttleMs { number } 节流限制的时间,单位(毫秒) */ export function throttle(fn: Function, throttleMs: number = 200) { let drop = false; return () => { if (!drop) { drop = true; setTimeout(() => { drop = false; }, throttleMs); fn(); } }; } |
防抖和节流是鸿蒙应用开发中提升性能的利器。通过合理使用防抖和节流,可以有效优化事件处理、输入框输入、网络请求和滚动事件,从而提升应用的整体性能和用户体验。
现在低功耗蓝牙(BLE)连接都是建立在 GATT (Generic Attribute Profile) 协议之上。GATT 是一个在蓝牙连接之上的发送和接收很短的数据段的通用规范,这些很短的数据段被称为属性(Attribute)。
详细介绍 GATT 之前,需要了解 GAP(Generic Access Profile),它在用来控制设备连接和广播。GAP 使你的设备被其他设备可见,并决定了你的设备是否可以或者怎样与合同设备进行交互。例如 Beacon 设备就只是向外广播,不支持连接,小米手环就等设备就可以与中心设备连接。
GAP 给设备定义了若干角色,其中主要的两个是:外围设备(Peripheral)和中心设备(Central)。
外围设备:这一般就是非常小或者简单的低功耗设备,用来提供数据,并连接到一个更加相对强大的中心设备。例如小米手环。
中心设备:中心设备相对比较强大,用来连接其他外围设备。例如手机等。
在 GAP 中外围设备通过两种方式向外广播数据: Advertising Data Payload(广播数据)和 Scan Response Data Payload(扫描回复),每种数据最长可以包含 31 byte。这里广播数据是必需的,因为外设必需不停的向外广播,让中心设备知道它的存在。扫描回复是可选的,中心设备可以向外设请求扫描回复,这里包含一些设备额外的信息,例如设备的名字。(广播的数据格式我将另外专门写一个篇博客来讲。)
GAP 的广播工作流程如下图所示。

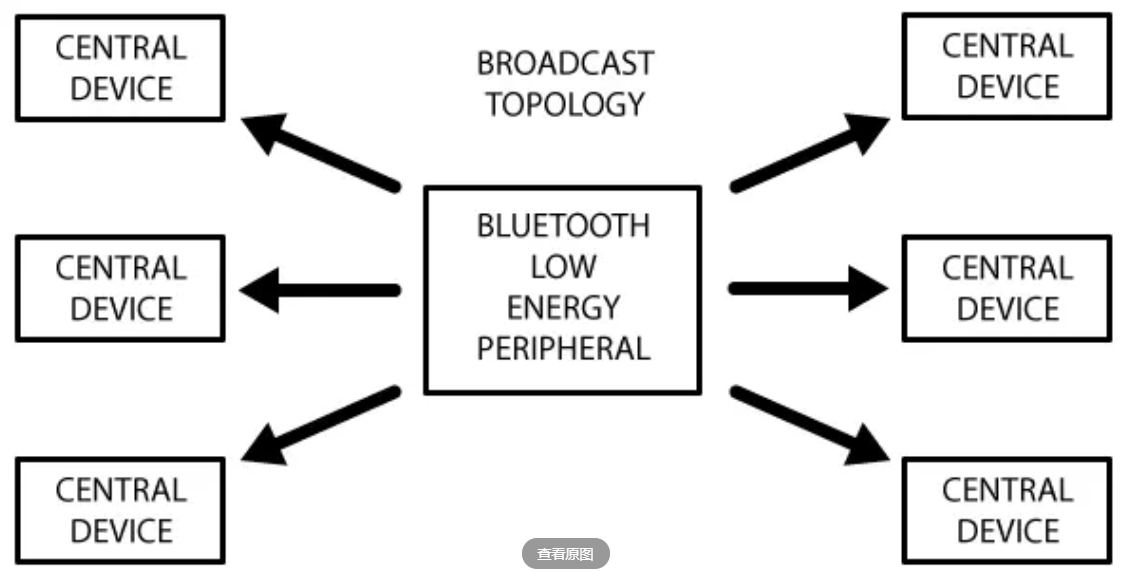
从图中我们可以清晰看出广播数据和扫描回复数据是怎么工作的。外围设备会设定一个广播间隔,每个广播间隔中,它会重新发送自己的广播数据。广播间隔越长,越省电,同时也不太容易扫描到。
大部分情况下,外设通过广播自己来让中心设备发现自己,并建立GATT连接,从而进行更多的数据交换。也有些情况是不需要连接的,只要外设广播自己的数据即可。用这种方式主要目的是让外围设备,把自己的信息发送给多个中心设备。因为基于GATT连接的方式的,只能是一个外设连接一个中心设备。使用广播这种方式最典型的应用就是苹果的iBeacon。广播工作模式下的网络拓扑图如下:
GATT 的全名是 Generic Attribute Profile(姑且翻译成:普通属性协议),它定义两个 BLE 设备通过叫做 Service 和 Characteristic 的东西进行通信。GATT 就是使用了 ATT(Attribute Protocol)协议,ATT 协议把 Service, Characteristic遗迹对应的数据保存在一个查找表中,次查找表使用 16 bit ID 作为每一项的索引。
一旦两个设备建立起了连接,GATT 就开始起作用了,这也意味着,你必需完成前面的 GAP 协议。这里需要说明的是,GATT 连接,必需先经过 GAP 协议。实际上,我们在 Android 开发中,可以直接使用设备的 MAC 地址,发起连接,可以不经过扫描的步骤。这并不意味不需要经过 GAP,实际上在芯片级别已经给你做好了,蓝牙芯片发起连接,总是先扫描设备,扫描到了才会发起连接。
GATT 连接需要特别注意的是:GATT 连接是独占的。也就是一个 BLE 外设同时只能被一个中心设备连接。一旦外设被连接,它就会马上停止广播,这样它就对其他设备不可见了。当设备断开,它又开始广播。
中心设备和外设需要双向通信的话,唯一的方式就是建立 GATT 连接。
下图展示了 GTT 连接网络拓扑结构。这里很清楚的显示,一个外设只能连接一个中心设备,而一个中心设备可以连接多个外设。
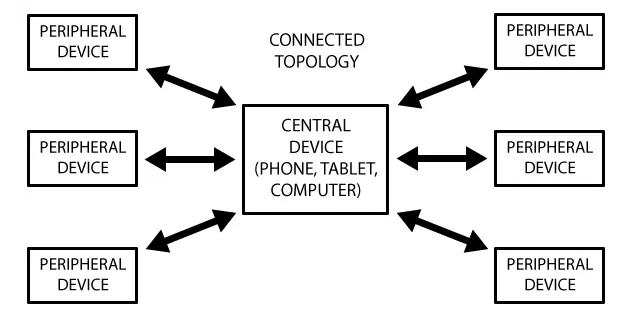
一旦建立了连接,通信就是双向的了,对比前面的GAP广播的网络塔扑,GAP通信是单向的。如果你要让两个外围设备能通信,就只能通过中心设备中转。
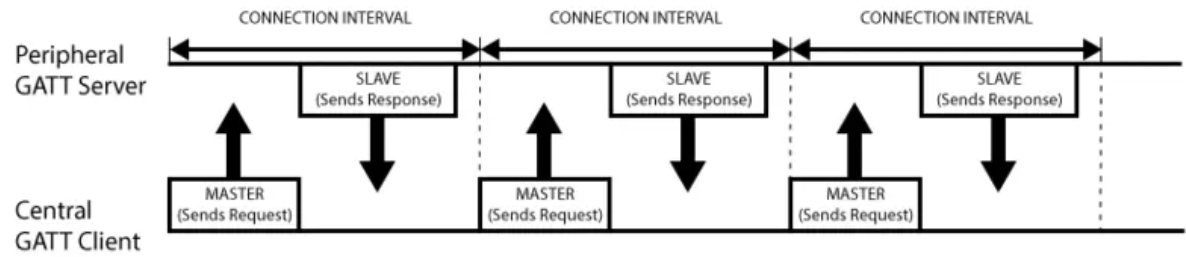
GATT通信的双方是C/S关系。外设作为GATT服务端(Server),它维持了ATT的查找表以及service和characteristic的定义。中心设备是GATT客户端(Client),他向Server发起请求。需要注意的是,所有的通信事件,都是由客户端(也叫主设备,Master)发起,并且接收服务端(也叫从设备,Slava)的响应。
一旦连接建立,外设将会给中心设备建议一个 连接间隔(Connection Interval),这样,中心设备就会在每个连接间隔尝试去重新连接,检查是否有新的数据。但是,这个连接间隔只是一个建议,你的中心设备可能并不会严格按照这个间隔来执行,例如你的中心设备正在忙于连接其他的外设,或者中心设备资源太忙。
下图展示一个外设(GATT服务端)和中心设备(GATT客户端)之间的数据交流流程,可以看到的是,每次都是主设备发起请求:
GATT事务是建立在嵌套的Profiles,Services和Characteristics之上的,如下如所示:
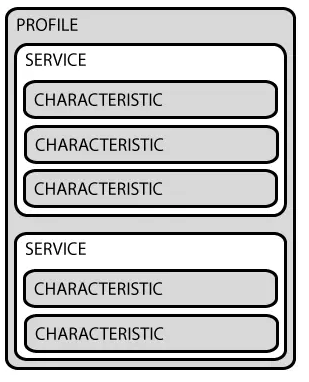
Profile Profile并不是实际存在于BLE外设上的,它只是一个被Bluetooth SIG或者外设设计者预先定义的Service的集合。例如心率Profile(Heart Rate Profile)就是结合了Heart Rate Service和Device Information Sercvice。所有官方通过GATT Profile的列表可以从这里找到。
Service Service是把数据分成一个个的独立逻辑项,它包含一个或者多个Characteristic。每个Service有一个UUID唯一标识。UUID有16bit的,或者128bit的。16bit的UUID是官方通过认证的,需要花钱购买,128bit是自定义的,这个就可以自己随便设置。
官方通过了一些标准Service,完整列表在这里。以Heart Rate Service为例,可以看到它的官方通过16bitUUID是 0x180D,包含3个Characteristic:Heart Rate Measurement,Body Sensor Location和Heart Control Point,并且定义了只有一个第一个必须的,它是可选实现的。
Characteristic 在GATT事务中的最低界别的是Characteristic,Characteristic是最小的逻辑数据单元,当然它可能包含一个组关联的数据,例如加速度计的X/Y/Z三轴值。与Service类似,每个Characteristic用16bit或者128bit的UUID唯一标识。你可以免费使用Bluetooth SIG官方定义的标准Characteristic,使用官方定义的,可以确保BLE的软件和硬件能相互理解。当然,你可以自定义Characteristic,这样的话,就只有你自己的软件和外设能够相互理解。
举个例子,Heart Rate Measurement Characteristic,这是上面提到的Heart Rate Service必需实现的Characteristic,它的UUID是 0x2A37。它的数据结构是,开始8bit定义心率数据格式(是UINT8还是UINT16?),接下来就是对应格式的实际心率数据。
实际上,和BLE外设打交道,主要是通过Characteristic。你可以从Characteristic读取数据,也可以往Characteristic写数据。这样就实现了双向的通信。所以你可以自己实现一个类似串口(UART)的service,这个Service中包含两个Characteristic,一个被配置只读的通道(RX),另一个配置为只写的通道(TX)。
Bluetooth SIG 官方文档
移动开发资源
徒手用 1000 行 C 语言实现,不依赖庞大的外部库,Mac 即可运行。
如今这年头,徒手写神经网络代码已经不算事儿了,现在流行手搓大模型训练代码了!这不,今天,特斯拉前 AI 总监、OpenAI 创始团队成员 Andrej Karpathy 仅用 1000 行简洁的 C 代码,就完成了 GPT-2 大模型训练过程。
继续阅读“真男人就应该用 C 编程”!用 1000 行 C 代码手搓了一个大模型,Mac 即可运行,特斯拉前AI总监爆火科普 LLM
早期版本的 WordPress 内置了显示网站备案号的功能(WordPress 5.x 以及之前的版本,参考: 解决WordPress 5.2.3/5.7.2后台ICP备案链接不能跳转到工信部网站(www.miitbeian.gov.cn)的问题),但是升级到 WordPress 6.x 版本之后,这部分功能被丢弃了。
但是这又是工信部的规定,因此我们需要手工修改代码解决这个问题。
一般都是手工修改当前使用主题的 footer.php,增加工信部相关的配置,如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<div style="text-align:center"> <a href="https://beian.miit.gov.cn/" rel="external nofollow" target="_blank"> <?php // 根据域名的来源不同,返回不同的网站备案信息 $domain = $_SERVER['HTTP_HOST']; if((0 == strcasecmp('www.mobibrw.com', $domain)) || (0 == strcasecmp('mobibrw.com', $domain))) { echo '浙ICP备12020288号-1'; //网站备案信息 } else { echo '浙ICP备12020288号-2'; } ?> </a> </div> |
完整的增加位置如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
<?php /** * The template for displaying the footer * * Contains the closing of the "site-content" div and all content after. * * @package WordPress * @subpackage Twenty_Fifteen * @since Twenty Fifteen 1.0 */ ?> </div><!-- .site-content --> <footer id="colophon" class="site-footer" role="contentinfo"> <div class="site-info"> <?php /* * Fires before the Twenty Fifteen footer text for footer customization. * * @since Twenty Fifteen 1.0 */ do_action( 'twentyfifteen_credits' ); ?> <div style="text-align:center"> <a href="https://beian.miit.gov.cn/" rel="external nofollow" target="_blank"> <?php // 根据域名的来源不同,返回不同的网站备案信息 $domain = $_SERVER['HTTP_HOST']; if((0 == strcasecmp('www.mobibrw.com', $domain)) || (0 == strcasecmp('mobibrw.com', $domain))) { echo '浙ICP备12020288号-1'; //网站备案信息 } else { echo '浙ICP备12020288号-2'; } ?> </a> </div> </div><!-- .site-info --> </footer><!-- .site-footer --> </div><!-- .site --> <?php wp_footer(); ?> </body> </html> |
安泰信8502D,热风枪焊台一体的,最近出了个问题:
焊台工作大概20分钟后频烦出现自动停止加热,回到待机状态,接着再开机立马就停,有的时候甚至开不了机,按键无反应!
断电几个小时候后再开机,还能用20分钟或半个小时,然后继续重复以上的故障现象。
{kind=link}
{kind=link}